python 爬虫四之静动态网页
- 爬虫最重要的就是如何请求自己想要的数据,但是数据并不是凭空产生的,而且在这个数据隐私利益上升的时代,爬虫与反爬虫的斗争逐渐升级到另外一个高度,这时突破反爬虫机制成了爬虫的难点.
- 从前的反爬虫机制比较单一,但是随着人们防范意识的提高,反爬虫越来越难,而且样式丰富,网页主要有下面两种方式
| 反爬虫方式 | 说明 | 星级 |
|---|---|---|
| 静态页面 | 所有数据在该网页上,最好获取 | ★★★ |
| 动态页面 | 数据和页面是分开异步请求的,目前大部分网页采用 | ★★★★★ |
静态界面
- 最初的大多数网站都是静态网址,除了提交表单,账户密码的需要请求后端时,基本的信息数据都在该网页里,所以只需要
get html,再加以文本处理就能简单的获取到自己想要的数据,然而现在大部分网页已经摒弃了这种用法,基本上的网页都是一个空框架,然后各种嵌入引用js文件进行渲染交互,优点是使网页更加美观,功能性更强,缺点就是数据的获取日益困难,各种加密阻碍了获取数据的道路.
单一数据获取方式
- 一个库就基本可以解决获取问题
1 |
|
定义静态参数网页
这个模式应该说一直有人在用,但是频率不是很高,最近我在某些网站上就遇到静态网页定义参数的方式,直接请求静态网页的同时,并生成了一些参数,后来网上搜索了一下静态网页的传参,有的是
cookies里面作为存储器,有的是headers里面传参,下面是post的data.直接先
post,发现了data里面有uid和username等陌生参数,直接搜索,发现了参数.
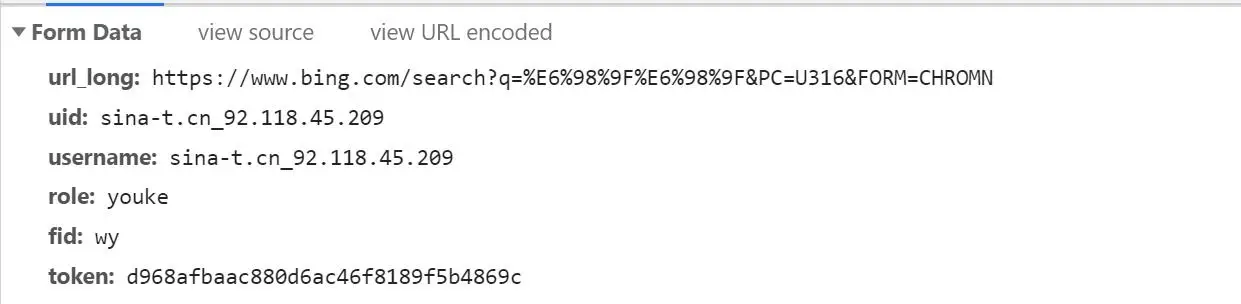
- 之前还以为是
js请求生成参数,结果发现竟然是静态网页直接生成参数,而且从js里面推测有次数限制调用.


- 此时我再次看到
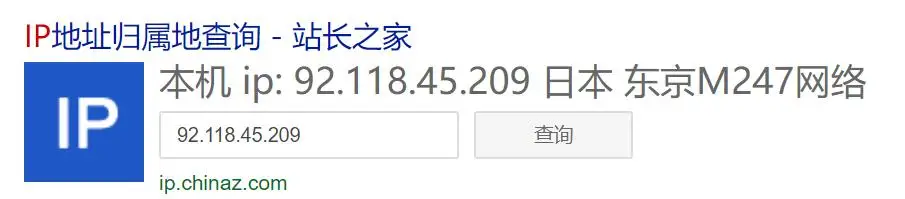
data时,我看到了username和uid中有一串数字:92.118.45.209可以推测可能是ip地址,这时直接ip查询,果然是日本,这里确认该该串数字是ip地址,因为我的代理是在日本的.

- 于是我又换了一个代理
ip,果然不出所料,是根据ip地址生成的token等参数,目前比较直接的解决方法就是直接上代理ip,然后requests.get(html)提取参数即可.

动态网页
关于动态,其实也可以理解为异步加载,可以理解为数据和网页是分开的,现在网页上最常用的交互模式.
最常用的模式:
js加密,可以对js生成参数的函数进行加密,混淆,以达到无法推测参数生成的目的,比如下面一个比较简单的例子.该
data中传入了一个奇怪的参数random,推测是js生成的,经过一番搜索得到了一个ajax请求


- 由上面的函数可以推测出一点信息,这个
random可能跟函数的随机数有关,接下来直接搜索random,发现了如下的内容,有个Math.floor(2147483648 * Math.random()这串数字,然后我就直接尝试post请求数据,发现行不通,显示状态过期.



- 可能是还有其他验证方式,再回到
data里面看看,发现数据位数不一样,可能缺少了其他步骤,再回去参考函数.
| 参数 | 请求 |
|---|---|
random |
218303204271012 |
现参数 |
1648297561 |
- 这时发现由函数a,b,c,d多个函数生成的,可以确定只可能是random的偏移值,这时,我推想可以是否直接用
data+偏移值=new_random进行请求数据呢,于是决定尝试一下.


- 取上述的数据
218303204271012+Math.floor(2147483648 * Math.random()请求数据,果然请求成功,基本可以推测出是修改某种偏移值来修改参数的,后来我又重新请求得到不同的原始值,但是都请求成功了,可以确定这种方法有效.


结束之感
- 虽然现在的动态页面数据很难获取,但是对于大部分网站来说,
js加密并不是搞得很复杂,还有验证码也是获取数据的一大难关,包括现在的大网站使用的扫码登陆,基本上让你无法从js文件中获取你想要的加密函数,爬虫之路还很长.