python爬虫五
- 基本了解爬虫的工作原理后,我觉得信息的获取是非常的不容易,当你只要轻轻一点浏览器的相关网址后,大量信息瞬间出现在屏幕上,这是一件非常神奇的事情,但是实际上后台已经在处理你的请求并返回
response,顺便进行了一系列的身份验证,防伪造虚假请求后在进行数据传输的,这是一个非常严谨的过程.
- 用markdown语法写作的人都知道,写作过程中不仅仅只是文字,毕竟有个成语叫做图文并茂,这里就涉及到了图床的概念,图床是存储图片的网络服务器,当我们只是想微量的使用图片资源时,是不必要考虑到自家搭建的图床源,网上有很多优秀的免费图床资源,然而由于某种限制,催发我这次要请求的数据.
分析过程
寻找网址
- 这是一个比较稳定的网址,有用户亲测16年的图片还有效,图床源确实比较稳定,下面是该图床的首页

- 可以看到这里官网提供了API上传服务,而且有用户身份
token认证,以及其他相关信息
分析请求
- 直接打开chrome调试控制台,点击
perverse log防止丢包
- 随便上传一个图片,先观察抓包情况.

- 首先可以直接使用过滤器,先进入xhr,大部分数据都是属于xhr类的,果然找到了仅有的一个网址,在看看
response,的确是数据图床请求.


- 这里我们可以尝试看看
post的是什么数据,直接滑下来查看Form Data,可以看到这么一个结果.
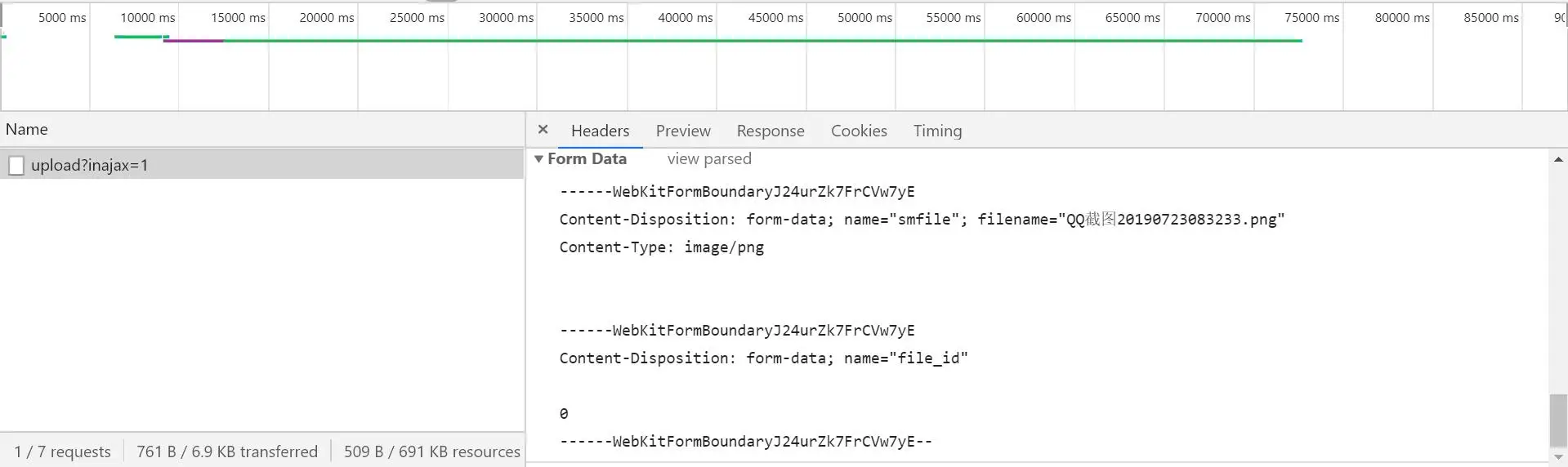
- 这个
WebKitFormBoundary是什么呢?直接搜索,按照网上这样子理解.
首先生成了一个
boundary用于分割不同的字段,为了避免与正文内容重复,boundary很长很复杂。然后Content-Type里指明了数据是以mutipart/form-data来编码,本次请求的boundary是什么内容。消息主体里按照字段个数又分为多个结构类似的部分,每部分都是以--boundary开始,紧接着内容描述信息,然后是回车,最后是字段具体内容(文本或二进制)。如果传输的是文件,还要包含文件名和文件类型信息。消息主体最后以--boundary--标示结束。
- 实际上就是直接分割数据段存储,这是
post方法中比较常用的,而且支持原生浏览器的请求表单的一种方式.那么该如何书写请求呢?我从requests官网中得到了解释.

- 根据官方文档说给的解释结合该网页的数据分段,我直接创建了如下的格式表单.

1 | self.data = { |
- 直接上请求,果然请求成功,返回了图片源地址,经测试没有问题.


总结一下
- 其实该网页可以考虑一下设置上传文件验证,但是似乎开销比较大,实际上
token认证也是一个不错的选择,毕竟自己的账户里面有自己的图片记录,防丢失是一个优点.